3.1 Reconnaissance de mots isolés
3.1.1 Introduction
Les modèles de Markov (Hidden Markov Models, HMM) nécessitent un apprentissage long—ce qui en soit n’est pas un problème—mais demandent aussi un corpus représentatif pour chaque mot à reconnaître, ce qui n’est pas sans poser quelques difficultés. En outre, la topologie du modèle de Markov est fixée a priori et n’est pas modifiée lors de l’apprentissage. En effet, seules les probabilités de transition entre les différents états et les probabilités d’observation à l’intérieur de ces derniers sont ajustées à l’aide des algorithmes classiques d’apprentissage dans les modèles de Markov. Le choix de la topologie initiale est donc un problème délicat. Des tentatives ont vu le jour pour introduire des connaissances phonétiques ou/et phonologiques lors de la construction de la topologie du modèle [1], [2].
La méthode que nous proposons est inspirée des premiers travaux en reconnaissance automatique de la parole, à l’époque où l’on utilisait un taux de dissemblance entre la locution à reconnaître et des locutions de référence, calculé grâce à la programmation dynamique. Les travaux ont pour origine la thèse de Joseph Di Martino [3] qui a utilisé les travaux de Sakoe et Chiba [4]. Cependant les coûts de cette technique sont élevés que ce soit en mémoire, pour sauvegarder les locutions de référence, ou en temps CPU à la reconnaissance. Par ailleurs l’article de Baum-Welch [5] à donné une preuve de convergence de l’algorithme du MLE (Maximum Likelihood Estimation) qui fut dès lors utilisé dans les modèles de Markov. Ceci a contribué au déclin de l’approche par programmation dynamique. Cependant en construisant un dictionnaire de vecteurs acoustiques (avec l’algorithme de quantification de Linde Buzo et Gray LBG [6]) puis en codant les locutions de référence tout en les factorisant à gauche, nous avons pu réduire l’espace mémoire et le temps de calcul requis ce qui permet d’obtenir de très bons résultats en reconnaissance de mots isolés comme nous allons le voir dans les sections suivantes.
3.1.2 Apprentissage
La base de donnée utilisée est TIDIGIT qui a servi à de nombreuses études. Le choix de cette base permet de comparer les résultats obtenus avec d’autres travaux. Le signal est échantillonné à  20kHz. La parole n’est pas bruitée. Le vocabulaire est formé des 11 chiffres anglo-saxons (o et zero pour le 0). Pour l’apprentissage, nous disposons de 55 locuteurs, des hommes adultes de divers états des USA. Chacun d’eux a prononcé deux fois l’ensemble des chiffres, ce qui fait 110 locutions de référence par mot. L’apprentissage s’effectue suivant les étapes suivantes :
20kHz. La parole n’est pas bruitée. Le vocabulaire est formé des 11 chiffres anglo-saxons (o et zero pour le 0). Pour l’apprentissage, nous disposons de 55 locuteurs, des hommes adultes de divers états des USA. Chacun d’eux a prononcé deux fois l’ensemble des chiffres, ce qui fait 110 locutions de référence par mot. L’apprentissage s’effectue suivant les étapes suivantes :
– paramétrisation du signal,
– construction du dictionnaire,
– construction de l’automate. Nous allons détailler ces trois étapes.
3.1.2.1 Paramétrisation du signal
Nous utilisons l’analyse cepstrale (cf. section 2.2.3) pour analyser le signal. Cette analyse suppose l’hypothèse couramment admise : le signal de parole ![]() résulte de la convolution de sources (vibrations des cordes vocales, bruit de friction) avec la fonction de transfert du conduit vocal.
résulte de la convolution de sources (vibrations des cordes vocales, bruit de friction) avec la fonction de transfert du conduit vocal.
Tous les 256 échantillons (16ms) nous extrayons du signal acoustique préaccentué
=x(i)-0.96x(i-1)")
des fenêtres de  échantillons ce qui correspond à une durée de 32ms—une puissance de deux étant idéale pour la FFT (Fast Fourier Transform)— Le fenêtrage utilisé est celui de Hamming
échantillons ce qui correspond à une durée de 32ms—une puissance de deux étant idéale pour la FFT (Fast Fourier Transform)— Le fenêtrage utilisé est celui de Hamming
![h(i)=0.54-0.46\cos \left( \frac{2\pi i}{N-1}\right) ,\, i\in [0,N-1]](sites/bruno/local/cache-TeX/3720004de8fdd0311260184a5282fc92.png?1663819715 "h(i)=0.54-0.46\cos \left( \frac{2\pi i}{N-1}\right) ,\, i\in [0,N-1]")
et
=0,\, i\geq N") . La transformée de Fourier à court terme de
. La transformée de Fourier à court terme de ![]() ,
,
=\sum _{i=-\infty }^{\tau }s(i)h(\tau -i)e^{-\frac{2\pi fi}{N}}")
est calculée pour ![]() compris entre 0 et la fréquence de Nyquist
compris entre 0 et la fréquence de Nyquist
 10kHz. Puis nous calculons le logarithme
10kHz. Puis nous calculons le logarithme
") défini par
défini par
=\log (\left\vert z\right\vert )+j\arg (z)") où
où  . Enfin nous intégrons ce logarithme suivant 20 canaux répartis selon une échelle fréquentielle non linéaire mel :
. Enfin nous intégrons ce logarithme suivant 20 canaux répartis selon une échelle fréquentielle non linéaire mel :
\, Hz")
où ![]() est la fréquence en Hz et
est la fréquence en Hz et ![]() la fréquence en mel. Cette échelle a l’ambition de modéliser la sensibilité de l’oreille humaine. Une transformée de Fourier inverse fournit les coefficients. Les premiers d’entre eux, qui contiennent le plus d’information au sujet de la fonction de transfert du conduit vocal, sont conservés 23.
la fréquence en mel. Cette échelle a l’ambition de modéliser la sensibilité de l’oreille humaine. Une transformée de Fourier inverse fournit les coefficients. Les premiers d’entre eux, qui contiennent le plus d’information au sujet de la fonction de transfert du conduit vocal, sont conservés 23.
Ainsi nous obtenons un vecteur de paramètres MFCC (Mel Frequency scaled Cepstral Coefficient)
 toutes les 16ms. L’étape suivante consiste à quantifier cet espace i.e. à trouver l’ensemble de prototypes
toutes les 16ms. L’étape suivante consiste à quantifier cet espace i.e. à trouver l’ensemble de prototypes
 le plus représentatif de cet ensemble de vecteurs.
le plus représentatif de cet ensemble de vecteurs.
3.1.2.2 Construction du dictionnaire
Nous utilisons l’algorithme LBG (Linde Buzo Gray 56). La construction est itérative : le premier prototype
 est le centre de gravité de l’ensemble des vecteurs cepstraux, la première partition est constituée d’une seule partie. Puis nous divisons chaque partie en deux, itérativement, jusqu’à l’obtention du nombre de classes voulu.
est le centre de gravité de l’ensemble des vecteurs cepstraux, la première partition est constituée d’une seule partie. Puis nous divisons chaque partie en deux, itérativement, jusqu’à l’obtention du nombre de classes voulu.
– Calcul du centre de gravité
de l’espace, 
– Une légère perturbation de
 donne
donne
 pour
pour 
– Partition de l’espace :
 pour
pour ![i\in [1,N]](sites/bruno/local/cache-TeX/320fc36a1f0930aab2a3db6f3b24429f.png?1663819718 "i\in [1,N]")
– Calcul de la nouvelle distorsion
 et de leurs centres de gravité
et de leurs centres de gravité

– Si
 alors on remplace
alors on remplace  par
par  , on remplace
, on remplace
 et on retourne en 3
et on retourne en 3
– Tant que
À l’aide des codebooks obtenus, nous codons les locutions en remplaçant chaque vecteur par l’indice du prototype le plus proche. Nous obtenons ainsi un ensemble de suites de vecteurs prototypes comme modèle pour chacun des mots. Par exemple, sur la figure 3.1, l’ensemble des vecteurs cepstraux est partitionné en 4 classes. La locution représentée par la flèche—qui donne le sens du temps— sera codée 4, 3, 2, 2, 2, 2, 1, 1, 1, 4, 1.
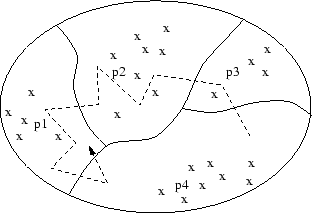
Construction d’un dictionnaire et codage d’une locution
|
3.1.2.3 Construction de l’automate
Pour chaque mot, nous construisons un automate en factorisant à gauche les locutions codées [7]. Cependant, afin de réduire au maximum la place mémoire nécessaire—et par conséquent le temps CPU requis pour reconnaître une locution—nous introduisons des boucles quand 4 prototypes identiques sont consécutifs. Ceci permet aussi de contraindre l’alignement temporel de telle sorte que les zones les plus stables du signal soient les plus sujettes aux dilatations et aux contractions. La figure 3.2 illustre la construction d’un tel automate. Elle représente le codage de deux locutions d’un mot et l’automate correspondant. On remarque que le premier prototype
est factorisé. Deux boucles ont été introduites dans les parties stables du signal : pour le prototype
 dans la première locution et pour
dans la première locution et pour
dans la seconde.
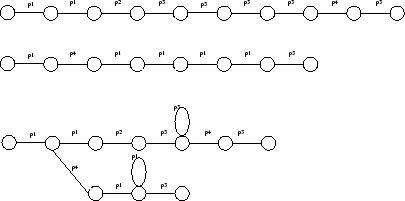
En haut deux locutions, en bas l’automate correspondant
|
3.1.3 Reconnaissance
Dans la base TIDIGIT, nous disposons d’un ensemble de 56 locuteurs disjoint de celui qui a servi à l’apprentissage. Ces locuteurs ont prononcé deux fois chaque mot ce qui fait
 mots isolés à reconnaître. Comme pour l’apprentissage, ces locutions sont paramétrisées en utilisant les MFCC. Puis elles sont codées suivant les prototypes de chacun des modèles. Enfin pour chaque locution, nous comparons son codage à l’automate du mot correspondant en utilisant la programmation dynamique.
mots isolés à reconnaître. Comme pour l’apprentissage, ces locutions sont paramétrisées en utilisant les MFCC. Puis elles sont codées suivant les prototypes de chacun des modèles. Enfin pour chaque locution, nous comparons son codage à l’automate du mot correspondant en utilisant la programmation dynamique.
Nous allons commencer cette section par la description du principe utilisé, puis nous décrirons les résultats obtenus :
– comparaison du taux de reconnaissance avec des résultats obtenus en utilisant un modèle de Markov discret, et incrémentalité de l’apprentissage,
– influence de la dérivée des vecteurs cepstraux, quantification des références et reconnaissance temps réel. Enfin, avant de décrire l’extension de la méthode au problème de la reconnaissance de mots enchaînés, nous discuterons ces résultats.
3.1.3.1 Principe de la reconnaissance
Nous mesurons un taux de dissemblance entre la locution à reconnaître et chacun des automates. Le mot reconnu est celui dont le modèle donne le plus petit taux de dissemblance3.1. Celui-ci est défini comme étant le minimum des taux de dissemblance entre la locution à reconnaître et chacune des branches de l’automate. Le taux de dissemblance entre une locution paramétrisée
 ,
,
 et une suite de prototypes
et une suite de prototypes
 ,
,  est défini par :
est défini par :
=\min _{W}(\sum ^{K}_{k=1}\frac{d(\overrightarrow{c}_{W_{i}(k)},\overrightarrow{p}_{W_{j}(k)})P(W(k-1),W(k))}{N(W)})")
où
") est un chemin de recalage, c’est-à-dire une fonction de
est un chemin de recalage, c’est-à-dire une fonction de ![[1,\ldots,K]](sites/bruno/local/cache-TeX/ea6cec4cfc6d3fa1be3fd65a87eaeed6.png?1663819720 "[1,\ldots,K]") dans
dans
![[1,\ldots,N]\times [1,\ldots,M]](sites/bruno/local/cache-TeX/207994669a52e4d234665388f474d4ce.png?1663819720 "[1,\ldots,N]\times [1,\ldots,M]") croissante au sens large (pour rendre compte de l’écoulement du temps) et telle que
croissante au sens large (pour rendre compte de l’écoulement du temps) et telle que =(1,1)") et
et =(N,M)") .
. ") est une distance dans l’espace des vecteurs cepstraux, nous avons utilisé une distance euclidienne.
est une distance dans l’espace des vecteurs cepstraux, nous avons utilisé une distance euclidienne.
![]() est une pondération qui dépend de contraintes locales imposées à
est une pondération qui dépend de contraintes locales imposées à ![]() et
et
=\sum ^{K}_{k=1}P(W(k-1),W(k))")
est un facteur de normalisation rendant
") indépendant de la longueur du chemin.
indépendant de la longueur du chemin.
Ces chemins de recalage permettent de tenir compte des différents débits d’élocution en comparant des locutions de longueurs différentes de manière judicieuse. En effet le changement du débit d’élocution n’affecte pas également tout les phonèmes et par conséquent le recalage linéaire
 ne suffit pas. La figure 3.3 donne un exemple de recalage temporel.
ne suffit pas. La figure 3.3 donne un exemple de recalage temporel.
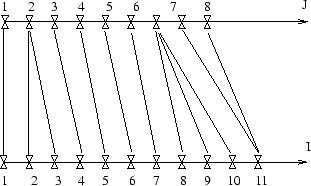
Recalage temporel
|
Mais le calcul des taux de dissemblance pour chacun des chemins est excessivement coûteux. En effet, il existe  chemins satisfaisant ces contraintes. Heureusement, la programmation dynamique permet le calcul du chemin optimal
chemins satisfaisant ces contraintes. Heureusement, la programmation dynamique permet le calcul du chemin optimal
![]() (qui minimise
(qui minimise
) avec un coût en ") opérations.
opérations.
Soit ![]() un chemin optimal qui conduit de
un chemin optimal qui conduit de ") à
à ") . Alors si
. Alors si \in W") , le chemin menant de à
, le chemin menant de à ![]() est lui aussi optimal.
est lui aussi optimal.
Maintenant, des contraintes assurent que chaque vecteur de la locution à reconnaître est mis en correspondance avec un prototype. Posons ") le chemin optimal entre
le chemin optimal entre ![]() et
et ![]() . Alors ce chemin est composé d’un chemin optimal
. Alors ce chemin est composé d’un chemin optimal
") et d’un chemin entre
et d’un chemin entre ") et
et ![]() . On peut donc calculer pour chaque
. On peut donc calculer pour chaque ![]() tous les chemins optimaux tels que
tous les chemins optimaux tels que  . La recherche du chemin optimal est donc en
. La recherche du chemin optimal est donc en
. En outre, il suffit maintenant de mémoriser  taux de dissemblance car les coûts des chemins arrivant en
taux de dissemblance car les coûts des chemins arrivant en ") ne sont pas utilisés pour calculer les coûts de ceux qui aboutissent en
ne sont pas utilisés pour calculer les coûts de ceux qui aboutissent en ![]() .
.
La figure 3.4 présente trois exemples de contraintes locales, ainsi que les pondérations ![]() . Deux types de pondérations sont habituellement choisis :
. Deux types de pondérations sont habituellement choisis :
– les pondérations symétriques :
,W(k))=W_{i}(k)-W_{i}(k-1)+W_{j}(k)-W_{j}(k-1)") donc
donc
=W_{i}+W_{j}")
– les pondérations asymétriques :
,W(k))=W_{i}(k)-W_{i}(k-1)") donc
donc
=W_{i}")
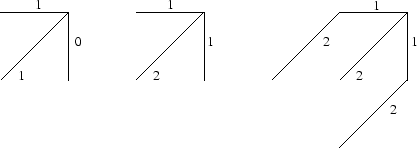
Contraintes locales : asymétrique, symétrique, de Sakoe et Chiba symétrique
|
Nous avons choisi des contraintes qui obligent les dilatations à s’effectuer dans les zones stables (où l’on a introduit des boucles). La figure 3.5 illustre un chemin optimal possible satisfaisant ces contraintes.
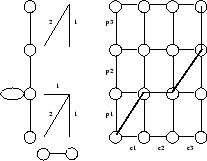
Les contraintes utilisées et un exemple de chemin
|
Voici l’algorithme de calcul du taux de dissemblance entre une locution et un automate :
Initialiserle cumul des distances le long du chemin optimal finissant à l’état j=0 de l’automate au temps i= 0 à 0
Pour i de 1à NInitialiser laà l’infini : contraindre le chemin optimal à débuter en (0,0)
Pour j de 1 au nombre d’états de l’automateCalculerle cumul des distances le long du chemin optimal finissant en
où
est un état prédécesseur de

Calculerla longueur de ce chemin en fonction des états prédécesseur de
Le taux de dissemblance vaut
où
La figure 3.6 illustre cet algorithme.
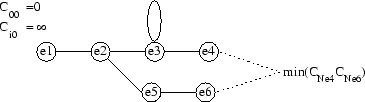
Principe de la reconnaissance de mots isolés
|
Enfin, le mot reconnu est celui dont le modèle donne le taux de dissemblance le plus petit.
3.1.3.2 Incrémentalité de l’apprentissage
Une des difficultés rencontrées lors de l’utilisation des modèles de Markov est la réestimation des paramètres (moyenne et matrice de covariance à l’intérieur des états pour les modèles semi-continus et probabilités de transition). En effet, étant donnée la manière dont s’effectue l’apprentissage, les locuteurs mal représentés dans le corpus, ou les conditions différentes (milieux bruités, microphones différents lors de l’acquisition du corpus d’apprentissage et de la reconnaissance...) font chuter le pourcentage de mots reconnus. Nous avons donc testé la possibilité pour notre système d’apprendre à corriger ses erreurs. Pour cela, les locutions mal reconnues sont codées puis ajoutées dans le modèle correspondant.
En utilisant 23 coefficients cepstraux et 256 prototypes, nous avons obtenu un taux de reconnaissance de 98.5% soit 19 erreurs sur 1232 locutions à reconnaître. Ces résultats sont comparables aux 99.4% obtenus en utilisant des modèles de Markov discrets [8]. Après adjonction de ces 19 locutions dans les automates correspondants, seules 4 erreurs subsistaient, soit un taux de reconnaissance de 99.9%.
3.1.3.3 Reconnaissance temps réel
À chaque instant, notre algorithme effectue autant de calculs de distance qu’il y a de vecteurs prototypes, et autant de comparaisons qu’il y a d’états dans les automates. Le nombre de prototypes étant fixé, le coût croît de façon linéaire en fonction du nombre d’états.
Pour réduire la place mémoire ainsi que le temps CPU nécessaires à la reconnaissance d’un mot, nous devons diminuer le nombre d’états, par exemple en choisissant un sous-ensemble des locutions de la base d’apprentissage comme locutions de référence. Pour cela nous avons développé un algorithme de quantification des formes de référence. D’autre part, certains auteurs ont remarqué que l’utilisation de la dérivée des coefficients cepstraux améliorait les taux de reconnaissance. Ceci est à rapprocher de l’utilisation de modèles de Markov d’ordre 2 ou des modèles de trajectoire de Gong [9]. L’amélioration des performances s’explique par l’apport d’information sur l’évolution des paramètres. Dans un premier temps nous allons présenter l’influence de la dérivée des paramètres puis nous décrirons l’algorithme de quantification des formes de référence.
3.1.3.4 Influence de la dérivée des coefficients cepstraux
Comme l’ont remarqué certains auteurs [10], la prise en compte d’informations sur la cinétique des paramètres améliore souvent les taux de reconnaissance. Nous avons donc utilisé la dérivée des coefficients cepstraux. Une pondération  a été calculée pour donner la même influence aux vecteurs cepstraux qu’à leur dérivée. La distance entre deux paramètres pour lesquels les vecteurs cepstraux sont respectivement
a été calculée pour donner la même influence aux vecteurs cepstraux qu’à leur dérivée. La distance entre deux paramètres pour lesquels les vecteurs cepstraux sont respectivement
 et
et
 , est
, est
+p_{1}d^{2}(\overrightarrow{u}^{’},\overrightarrow{v}^{’})}") . Cette distance est utilisée pour quantifier le nouvel espace et pour comparer les locutions aux références.
. Cette distance est utilisée pour quantifier le nouvel espace et pour comparer les locutions aux références.
Le tableau 3.1 donne les taux d’erreur obtenus en fonction du nombre de paramètres prototypiques retenus. En outre, nous avons utilisé seulement onze coefficients cepstraux.
|
3.1.3.5 Quantification des formes de référence
L’idée de cet algorithme est de choisir seulement certaines locutions dans l’espace d’apprentissage. Cela permet d’améliorer le temps de réponse du logiciel puisque le nombre de calculs de distance est réduit. Pour cela on cherche les points correspondant au diamètre maximum de l’espace des locutions, puis on choisit parmi les deux extrémités celle qui possède la plus proche locution voisine. On cherche un deuxième point de cette manière. Puis nous divisons l’espace en deux comme pour quantifier les vecteurs acoustiques. L’itération est similaire à celle de l’algorithme de quantification vectorielle.
Algorithme :
Soit ![]() l’ensemble des locutions de l’espace d’apprentissage.
l’ensemble des locutions de l’espace d’apprentissage.
– Chercher le premier prototype
") ,
,  .
.
– Chercher le second prototype
 de la même manière dans
de la même manière dans
 , initialiser la distorsion
, initialiser la distorsion
– Partitionner
 de
de 
\leq D(\overrightarrow{p},\overrightarrow{p}_{j})") ,
,
 et
et 
– Calculer la distorsion du codage et réitérer les étapes 3 et 4 tant que celle-ci diminue.
– Incrémenter
Dans l’expérience réalisée nous utilisons 22 coefficients (vecteurs cepstraux et leurs dérivées), et 32 prototypes issus de la quantification vectorielle. Le tableau suivant synthétise les résultats obtenus en fonction du nombre de formes de référence retenues.
|
Les tests ont été effectués sur un HP 9000/755. Nous constatons que le taux de reconnaissance croît avec le nombre de prototypes utilisés. Sachant que les locutions ont une durée de l’ordre de la seconde, nous pouvons effectuer la reconnaissance en temps réel avec 16 prototypes.
3.1.4 Conclusion
La méthode décrite ci-dessus a donné des résultats comparables à ceux obtenus en utilisant des modèles de Markov discrets. En outre, elle a l’avantage de ne pas nécessiter un corpus important pour l’apprentissage. Un second point fort de cette technique est la possibilité d’effectuer un apprentissage incrémental dans le sens où une locution mal reconnue peut facilement être insérée dans l’automate. Il serait ainsi possible d’envisager une adaptation au locuteur par exemple, mais pour cela il faudrait élaguer l’automate car la borne supérieure du nombre d’états est gigantesque.
Dans la partie suivante, nous allons décrire les modifications apportées à l’algorithme pour l’adapter à la reconnaissance de mots enchaînés.
Notes
[1] L. Deng and D. X. Sun.
A statistical approach to automatic speech recognition using the
atomic speech units contructed from overlapping articulatory features.
J. Acoust. Soc. Am, 95(5):2702-2719, May 1994.
[2] H. Strik.
Using articulatory knowledge in automatic speech recognition.
In Newsletter of the Center for Language Studies (CLS)
, pages 8-13.
[3] J. Di Martino.
Contribution à la reconnaissance globale de la parole : Mots isolés
et mots enchaînés.
Thèse de 3ème cycle, 1984.
[4] H. Sakoe and S. Chiba.
A dynamic programming approach to continuous speech recognition.
In Proc. IEEE Int. Conf. Acoust., Speech, Signal Processing,
Budapest, Hungary, 1971.
[5] L.E. Baum, T. Petrie, G. Soules, and N. Weiss.
A maximization technique occurring in the statistical analysis of
probabilistic functions of markov models.
In The Annals of Mathematical Statistics, volume 41, pages
164-171, 1970.
[6] Y. Linde, A. Buzo, and R. M. Gray.
An algorithm for the vector quantizer design.
IEEE. Trans. on Communication, com. 28(1), January 1980.
[7] J. di Martino, J.-F. Mari, B. Mathieu, K. Perot K., and K. Smaïli.
Which model for future speech recognition systems : Hidden markov
models or finite-state automata.
In Proceedings of the International Conference on Acoustics,
Speech and Signal Processing, volume 1, pages 633-635, Adelaïde, Australia,
April 1994.
[8] L. R. Rabiner and S. E. Levinson.
Isolated and connected word recognition theory and selected
applications.
IEEE Trans. on Communication, 29(5):621-659, 1981.
[9] M. Afify, Y. Gong, and J.-P. Haton.
Estimation of Mixtures of Stochastic Dynamic Trajectories :
Application to Continuous Speech Recognition.
Computer, Speech and Language, 1995.
[10] E.L. Bocchieri and J.G. Wilpon.
Disciminative feature selection for speech recognition.
Computer Speech and Language, 7:229-246, 1993.